Julia で統計解析 第 2 章 データの入出力¶
Version()
最新バージョン 2024-10-29 13:16
データをデータフレームへ読み込む¶
統計解析の対象となるデータは,データファイルとして用意され,統計解析プログラム(Julia や R や Python)でコンピュータに読み込まれ,分析・処理される。
ここでは,データファイルがどのようになっているかを見ておく。
Excel のワークシートファイル¶
統計データに限らず,データの整理には,Excel などのスプレッドシートアプリが使われる。 ワークシートは二次元の行列のようにまとめられている。行には観察対象や年次のように繰り返されるものを割り当てる。 列はそれぞれの行において何種類かの観察値,測定値を割り当て,それぞれが何を表すかということで,変数ともいわれる。 変数は整数値,実数値,文字列のいずれかのデータを取る。 場合によっては同じ変数が幾つかの型のデータを取るような場合もあるが,最終的に集計・解析される時点では同じ型に変換される。
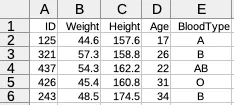
データファイルは,XLSX 形式(拡張子が .xlsx)で保存してかまわない。
XLSX 形式で保存されたファイル名を df.xlsx としたとき,XLSX パッケージを使用してデータフレーム df に読み込むことができる。
XLS 形式はサポートしていない。
using DataFrames, XLSX
df = DataFrame(XLSX.readtable("df.xlsx", "Sheet1"))
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Any | Any | Any | Any | Any | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
typeof(df.Weight)
Vector{Any} (alias for Array{Any, 1})
Any は最上位の型であり,特に他の型に変更する必要はないが,処理速度のパフォーマンスを上げるために変更したほうがよい場合もある。
実数型,整数型,文字列型への変更はそれぞれ float.(), Int.(), sring.() で行える。
なお,下の例のように列を参照するときには,データフレーム.列名 のような形式で参照する(他の参照法もあるがこれが一番簡潔)。
df.Weight = float.(df.Weight)
df.ID = Int.(df.ID)
df.BloodType = string.(df.BloodType)
5-element Vector{String}:
"A"
"B"
"AB"
"O"
"B"
df
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Int64 | Float64 | Any | Any | String | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
Any 型が必要な場合もある。その一つの例が,欠損値 missing を扱う場合である。missing は 実数型でも整数型でも文字列型でもないため,それらの型を持つ変数へ代入することができない。
typeof(missing)
Missing
# df.Weight[1] = missing # これは,エラーになる
# MethodError: Cannot `convert` an object of type Missing to an object of type Float64
df.Height の型は Any なので,missing を代入できる。
df.Height[1] = missing # これはエラーにならない
missing
CSV ファイル¶
上述のように XLSX 形式のワークシートファイルは XLSX.readtable() によって直接読み込むこともできるが,XLS 形式のワークシートには対応していない。
また,Excel のバージョンアップなどで,XLSX.readtable() が対応できなくなる可能性もある。
このようなことから,一般性を保証するためには CSV 形式(拡張子が .csv)で保存することが望ましい。
典型的な CSV ファイル¶
CSV ファイルは以下のようになっている。1 行目に変数名,2 行目以降にデータが,それぞれカンマで区切られている。
ID,Weight,Height,Age,BloodType
125,44.6,157.6,17,A
321,57.3,158.8,26,B
437,54.3,162.2,22,AB
426,45.4,160.8,31,O
243,48.5,174.5,34,B
これをデータフレームとして読み込むのは,以下のようにする。
using CSV, DataFrames
df = CSV.read("df.csv", DataFrame)
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Int64 | String3 | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
データフレームの各列の型は,実際に入力されるデータから推論され妥当なものになっている。
当然,前述したように,Any 型以外の場合には missing は代入できない。
一般の CSV ファイル¶
CSV ファイルは Excel ファイルの一般的な保存形式ということに限らず,単に,前述したような 1 行目に変数名,2列目以降にデータをカンマで区切って列挙したものということである。
Excel を使わずとも単純なエディタで CSV ファイルをつくることもできる。
また,世の中にある CSV ファイルの中には CSV.read(ファイル名, DataFrame) だけでは読み込めないものもある。
CSV.read の引数¶
それらに対応するために CSV.read() が持っているいくつかのオプション(引数)についてまとめておこう。詳しくは csv.juliadata.org を参照。
header=整数
列名の定義について指定する。省略されている場合は,適当に解釈される。
列名が何行目に定義されているかを指定する。
デフォルトではheader=1。
2 以上の値が指定されたときはそれまでの行は読み飛ばされる。
また,列名の指定行のすぐ後からデータが始まると解釈されるので,もし読み飛ばすべき行があるならば,skiptoでデータ開始行を指定する。
例df = CSV.read("small.csv", DataFrame, header=0, skipto=2)header=0もしくはheader=false
列名を持たないファイルの場合は,列名を自動生成することができる。
例df = CSV.read("small.csv", DataFrame, header=0)header=["ab", "cd", ...]
文字列ベクトルで列名を定義する。
例df = CSV.read("small.csv", DataFrame, header=["a1", "b1", "c1"])header=[:ab, :cd, ...]
シンボルベクトルで列名を定義する。
例df = CSV.read("small.csv", DataFrame, header=[:a, :b, :c]])skipto
データが始まる行番号を指定する。footerskip
データの最後の何行を読み飛ばすかを指定する。limit
入力行数の制限transpose=false
行と列を転置して入力する。comment
指定した文字列から始まる行を(コメント行として)読み飛ばす。ignoreemptylines=true
空行を読み飛ばすselect
選択する列をベクトルで指定する。
select=[1, 3]列番号で指定
select=[:a, :c]列シンボルで指定
select=["a", "c"]列名で指定
select=[true, false, true]論理値で指定
select=(i, nm) -> i in (1, 3)ラムダ式(無名関数)で指定drop
選択しない列をベクトルで指定する(selectの逆である)。missingstrings,missingstring
欠損値を表す文字列を指定する。R ではNAが自動的に欠損値扱いになるが,Julia では特別に指定しないといけないので注意が必要である。
missingstring="-999"
missingstrings=["-999", "NA"]delim=','
データのデリミターをシングルクオートでくくって指定する。
最初の 10 行を見て,カンマ(,),タブ(\t),半角空白(' '),コロン(:),セミコロン(;),連結 concatenation(|) のどれかをデリミターと解釈する。
delim="@@@"のように文字列も使えるignorerepeated=false
連続するデリミタを無視するかどうかを指示する。
複数の空白で桁位置を揃えて入力されたファイルを読むときなどには,delim=' ', ignorerepeated=trueを指定すればよい。quotechar='"'
文字列をくくる引用符である。escapechar='"'
引用符のエスケープ文字である。dateformat
日付,時間のフォーマットを示す文字列である。
dateformat="yyyy/mm/dd"などdateformats
日付,時間のフォーマットを辞書型で示す。decimal='.'
小数点を表す文字をシングルクオートでくくって指定する。truestrings=["T", "TRUE"]
trueの他に真値を表す文字列を定義する。falsestrings=["F", "FALSE"]
falseの他に真値を表す文字列を定義する。type
ファイル全体に共通する唯一のデータ型を指定する。
項目全て(全列)をここで指定した型として読む。
実数データ行列を読むときにtype=Float64のように指定する。整数の場合はInt,文字列の場合はStringである。types
列ごとのデータ型を指定する。
ベクトルで与える場合は,全ての列について指定する。
types=Dict(3 => Int)3 列目の変数は整数ということを指定する。
types=Dict(:col3 => Int)3 列目の変数は整数ということを指定する。
types=Dict("col4" => Float64)"col4"という列の変数は実数であることを指定する。
types=[Int, Float64, String]typemap
特定の型の入力値を別の型として読み込む。
型のマッピングDict(Float64=>String)のように指定する。
typemap=Dict(Int => String)整数を文字列として読み込む。
types=Dict(:zipcode => String)郵便コードを文字列として読み込む。pool
lazystrings=falsestrict=false
不正な値は警告してmissingにするsilencewarnings=false
strict=falseのとき,不正な値の警告はしないmaxwarnings=100
警告を表示する最高回数
インターネット上の CSV ファイル¶
インターネット上にある CSV ファイルを読み込むのは以下のようにする。
なお,何回もサイトにアクセスするのは良くないので,読み取ったデータフレームを 「2. データフレームを CSV ファイルに書き出す」によって保存し,以後はダウンロードしたデータを使用するようにしたい。
using CSV, DataFrames, HTTP
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv"
tips = DataFrame(CSV.File(HTTP.get(url).body));
モニター上に表示された表をデータフレームに読み込む¶
ブラウザで表示した Web ページや,Word などの文章中に含まれる,見かけが表のようなデータをデータフレームとして読み取りたいことがある。
例えば,今見ている文書の「1.2. CSV ファイル」節に 2 つのデータの表示がある。
ID,Weight,Height,Age,BloodType
125,44.6,157.6,17,A
321,57.3,158.8,26,B
437,54.3,162.2,22,AB
426,45.4,160.8,31,O
243,48.5,174.5,34,B
と
df
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Int64 | String3 | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
である。
まず,これを CSV ファイルとして保存する。
それぞれをコピーしてテキストエディタにペーストし,たとえば data1.csv,data2.csv という名前で保存する。
行頭,行末に複数の空白があるような場合にはテキストエディタではなく Excel などのワークシートアプリに読み込ませればデータ部分を取り出すのが容易になることもある。同時にいくばくかの編集も行うことができる。その後 CSV ファイルとして保存すればよい。
データファイルに読み込むには,CSV.read() を用いる。保存した CSV ファイルが,何らかの点で標準のものと違う場合には,それに対応するために前節の CSV.read() の引数を使用する。
data1.csv は,1 行目に変数名,2行目以降にデータという構成の標準的な CSV ファイルなので,簡単に読み込める。
using CSV, DataFrames
df1 = CSV.read("data1.csv", DataFrame)
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Int64 | String3 | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
data2.csv はデータ部分の最も左の列は本来のデータではなくデータフレームでの通し番号である。1 行目の変数名にはこれが含まれない。
このデータを読み込むための対処法はいくつかある。
data2.csvをテキストエディタで開いて,一行目の変数名の最初に任意の(他と重複しない)変数名を付け加える。data2.csvをテキストエディタで開いて,データ部分の最初の列を削除する。CSV.read()の引数headerで列名を定義する。
どれも一長一短であるが,最後の選択肢がわかりやすいかもしれない。
df2 = CSV.read("data2.csv", DataFrame, header=[:No, :ID, :Weight, :Height, :Age, :BloodType], skipto=3)
| Row | No | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|---|
| Int64 | Int64 | Float64 | Float64 | Int64 | String3 | |
| 1 | 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 5 | 243 | 48.5 | 174.5 | 34 | B |
もし,このような煩わしい処理が何度も必要であれば,以下のような Julia プログラムを用意すればよい。
- このプログラムは,まず CSV ファイルの 1 行目から列名を読む。
- 次に,
skipto以降のデータから 1 列目を除いて列名なしのデータフレームとして読む。 - 最後に,データフレームの列名を付けて,返す。
function readcsvfile(fn; skipto=3)
f = open(fn, "r")
names = split(readline(fn))
close(f)
df = CSV.read(fn, DataFrame, header=0, skipto=skipto, drop=[1])
rename!(df, names)
df
end;
使用法は次のようにする。skipto はデフォルトで 3 になっているので,それ以外のときには明示指定する。
df = readcsvfile("data2.csv")
| Row | ID | Weight | Height | Age | BloodType |
|---|---|---|---|---|---|
| Int64 | Float64 | Float64 | Int64 | String3 | |
| 1 | 125 | 44.6 | 157.6 | 17 | A |
| 2 | 321 | 57.3 | 158.8 | 26 | B |
| 3 | 437 | 54.3 | 162.2 | 22 | AB |
| 4 | 426 | 45.4 | 160.8 | 31 | O |
| 5 | 243 | 48.5 | 174.5 | 34 | B |
クリップボードにコピーした内容をデータフレームにする¶
モニターに表示された標準的なデータフレームの形式をしたデータをデータフレームに読み込む。
このような場合は,CSV.read() の第 1 引数として,ファイル名ではなく IOBuffer(clipboard()) を指定すれば良い。
使用法は,たとえば以下のようなデータフレーム様の部分を control+C(Windows の場合は Ctrl+C)でコピーして,すぐに,
df = CSV.read(IOBuffer(clipboard()), DataFrame)
を実行する。
以下の 3 行は,カンマで区切られたデータフレーム様の場合である。これをコピーし,
foo,bar,baz 1,2,3 4,5,6
次の 1 行のプログラムを実行する。
# df = CSV.read(IOBuffer(clipboard()), DataFrame)
次の例は,空白で区切られたデータフレーム様の場合である。
CSV.read() の引数で,delim=' ', ignorerepeated=true を使用する。
なお,見た目が空白でも,全角空白やタブで区切られている場合があるので必ずしも簡単に読めるわけではない。そのような場合には,一旦 CSV ファイルとして保存し,ファイルに必要な修正を加えた後 CSV.read() する。
以下をコピーし,
foo bar baz 1 2 3 4 5 6
次の 1 行のプログラムを実行する。
# df = CSV.read(IOBuffer(clipboard()), DataFrame, delim=' ', ignorerepeated=true)
文字列行から入力する¶
Julia はプログラム中に,三重のダブルクオート """ で区切られた複数行の文字列を書くことができる。また,文字列から入力する機能もある。これを組み合わせれば,以下のようなことができる。
前節 1.5. の方法は,クリップボードを使うので一時的で再現性に劣る。しかし,この方法によればプログラム中にクリップボードに取り込んだものを残しておくことができる。
io = IOBuffer("""
Habitat,Site,morph_colour,number
Rural,R1,black,10
Rural,R2,black,3
Rural,R3,black,4
Rural,R4,black,7
Rural,R5,black,6
Rural,R1,red,15
Rural,R2,red,18
Rural,R3,red,9
Rural,R4,red,12
Rural,R5,red,16
Industrial,U1,black,32
Industrial,U2,black,25
Industrial,U3,black,25
Industrial,U4,black,17
Industrial,U5,black,16
Industrial,U1,red,17
Industrial,U2,red,23
Industrial,U3,red,21
Industrial,U4,red,9
Industrial,U5,red,15""")
using CSV, DataFrames
lb = CSV.read(io, DataFrame)
| Row | Habitat | Site | morph_colour | number |
|---|---|---|---|---|
| String15 | String3 | String7 | Int64 | |
| 1 | Rural | R1 | black | 10 |
| 2 | Rural | R2 | black | 3 |
| 3 | Rural | R3 | black | 4 |
| 4 | Rural | R4 | black | 7 |
| 5 | Rural | R5 | black | 6 |
| 6 | Rural | R1 | red | 15 |
| 7 | Rural | R2 | red | 18 |
| 8 | Rural | R3 | red | 9 |
| 9 | Rural | R4 | red | 12 |
| 10 | Rural | R5 | red | 16 |
| 11 | Industrial | U1 | black | 32 |
| 12 | Industrial | U2 | black | 25 |
| 13 | Industrial | U3 | black | 25 |
| 14 | Industrial | U4 | black | 17 |
| 15 | Industrial | U5 | black | 16 |
| 16 | Industrial | U1 | red | 17 |
| 17 | Industrial | U2 | red | 23 |
| 18 | Industrial | U3 | red | 21 |
| 19 | Industrial | U4 | red | 9 |
| 20 | Industrial | U5 | red | 15 |
エンコーディングの違うファイルを読む¶
Windows で作られた(変数名などに)日本語を含むファイル(インターネットからダウンロードしたファイルや研究チームで共有するファイル)は,以下のようにして読む(エンコーディングとして,shift_jis ではなく,cp932 を指定する)。
以下のような cp932 で保存された CSV ファイルを読む。
日本語,ファイル,数値
1,2,3
4,5,6
CSV.read("cp932.csv", DataFrame) では,日本語による変数名が文字化けしており,ちゃんと読めていない。
df = CSV.read("cp932.csv", DataFrame)
| Row | \x93\xfa\x96{\x8c\xea | \x83t\x83@\x83C\x83\x8b | \x90\x94\x92l |
|---|---|---|---|
| Int64 | Int64 | Int64 | |
| 1 | 1 | 2 | 3 |
| 2 | 4 | 5 | 6 |
以下のようにすれば読める。
using StringEncodings
df = CSV.File(open(read, "cp932.csv", enc"cp932")) |> DataFrame
| Row | 日本語 | ファイル | 数値 |
|---|---|---|---|
| Int64 | Int64 | Int64 | |
| 1 | 1 | 2 | 3 |
| 2 | 4 | 5 | 6 |
Julia, R, Python においても,最近ではエンコーディングはほとんど utf-8 に統一されている。
毎回いちいち cp932 と指定して読み込むより,いっそのこと utf-8 にしてしまえばよい。
方法は色々あるが,保存時にエンコーディングを選べるエディタで読み込み,utf-8 で保存する。
または,コマンドラインで nkf が使えるようであれば
% nkf -w cp932.csv > utf8.csv
のようにエンコードを変換する。
nkf コマンドのインストールは https://qiita.com/ponsuke0531/items/d0b6d743a70c624a1ba7 などを参照。
df = CSV.read("utf8.csv", DataFrame)
| Row | 日本語 | ファイル | 数値 |
|---|---|---|---|
| Int64 | Int64 | Int64 | |
| 1 | 1 | 2 | 3 |
| 2 | 4 | 5 | 6 |
デリミタで区切られていない固定書式ファイルを読む¶
たとえば,「1.2. CSV ファイル」節の最初に示したデータはカンマで区切られている。これに対して以下のようにカンマで区切られていないファイルがある。
ID,Weight,Height,Age,BloodType 12544.6157.617A 32157.3158.826B 43754.3162.222AB 42645.4160.831O 24348.5174.534B
このようなデータファイルは稀かもしれないが,たとえば 1 行に 0〜9 の値を持つ 100 変数のデータを考える。もし,数字をカンマで区切って入力するのはかなり煩雑な作業になる。これを,カンマで区切らずに長さ 100 の文字列として入力すればかなり省力できる。
そのようなデータの読み取りは特別な処理が必要である。R には fwf 関数があるが,Julia にはない(必要と思う人が自分で入力関数を書いている)ので,関数を書いた。
https://blog.goo.ne.jp/r-de-r/e/87cf94ca1ac03e36f5d92400691ef8b4 を参照して欲しい。
上のファイルに読み取りのための情報(2 行目)を加えて以下のようにする。
ID,Weight,Height,Age,BloodType i f f i s 12544.6157.617A 32157.3158.826B 43754.3162.222AB 42645.4160.831O 24348.5174.534B
ファイル名を sample2.dat として,以下のようにすればデータフレームに読み込むことができる。
julia> include("fixedformat.jl")
fixedformat (generic function with 1 method)
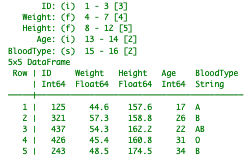
julia> df = fixedformat("sample2.dat")
データフレームを CSV ファイルに書き出す¶
入力されたデータはそのまま使われる場合もあるが,いろいろな編集や新たな変数の創生など元のデータとはかなり違いがでてくることも多い。毎回同じような手順を経てデータ分析に取り掛かるのは,無駄でもあるので,その時点のデータを別ファイルで保存しておき,次回以降はそのファイルからデータフレームに入力すればよい。
編集されたデータフレームの保存は簡単で,
CSV.write(ファイル, データフレーム)
とすればよい。
CSV.write("output.csv", df);
CSV.write の引数¶
CSV.write() の引数には,以下のようなものがある。詳しくは https://csv.juliadata.org/stable/ を参照。
bufsize=2^22
バッファーサイズdelim=','
デリミターquotechar='"'
引用符escapechar='"'
引用符のエスケープ文字missingstring=""
missingを表す文字列dateformat
dateformat="yyyy/mm/dd"などappend=false
既存のファイルに書き足すかどうかwriteheader=!append
列名を出力するかheader
使用する列名のリストnewline='\n'
改行文字quotestrings=false
文字列を引用符で囲むかどうかdecimal='.'
小数点として使用する文字